Tutorials Point Distributes Systes
Unit 1 architecture of distributed systems.1.Unit 1 Architecture of Distributed Systems 1 Architecture of Distributed SystemsIntroductionA Distributed System (DS) is one in which. Hardware and software components, located at remote networked computers, coordinate and communicate their actions only by passing messages. Any distance may separate computers in the network. Sharing of resources is the main motivation of distributed systems. Resources may be managed by servers and accessed by clients, or they may be encapsulated as objects and accessed by client objects.
The database connected to the distributed systems is quite complicated and difficult to handle as compared to a single user system. Overloading may occur in the network if all the nodes of the distributed system try to send data at once. Tutorial - Distributed Systems. Argument your answer. ( 1.5 points) Question 5.3 Adapt the central server algorithm for mutual exclusion to handle the crash failure of any client (in any state), assuming that the server is correct and given a reliable failure detector. Comment on whether the resultant system is fault tolerant.
A distributed operating system runs on multiple independent computers, connected through communication network, but appears to its users as a single virtual machine and runs its own OS. Computer Node Compute Computer Computer Compute Node Compute Node r r r Communication Network Computer Computer Node Compute Node Compute r r Fig: Architecturea Distributed System Architecture of of a Distributed SystemEach computer node has its own memory. Examples of Distributed Systems are: Internet, Intranet, Mobileand ubiquitous computing.
As a consequence of this definition, the characteristics of distributed systemsor networked-computers are:. Concurrency: How to handle the sharing of resources between clients? Execution of concurrent programs share resources: e.g. Web pages, files, etc.
No global clock: In a distributed system, computers are connected through network and have their own clocks. Communication between programs is only through messages and their coordination depends on time. Every clients (computer) perception of time is different. Accurate time synchronization is not possible in DS. How to synchronize activities?.
Independent Failure: Distributed systems should be planned for the consequences of possible failures of its components. How to handle a failure in the network or in a particular client? Other clients might not be immediately aware of a failure. Each component of the distributed system can.Unit 1 Architecture of Distributed Systems 2 fail independently leaving others still running. Faults in the network results in isolation of the failed component only, but system continue running.Characteristics of Distributed SystemsA Distributed System has the following characteristics:. It consists of several independent computers connected through communication network,. The computers communicate with each other by exchanging message over a communication network.
Each computer has its own memory, clock and runs its own operating system. Each computer has its own resources, called local resources. Remote resources are accessed through the networkWe will discuss issues that arise in the design of a distributed operating system and how communicationtakes place between the programs running on the connected computers.Motivation:The prime motivation of distributed systems is to share resources. A resource is an entity that can beusefully shared among users. Any hardware or software entity is a resource. We use shared resources allthe time.
Resources are managed by a service. A service is managed by one or more servers, whichprovide access to a set of resources to clients via a set of well-defined operations (an interface).The motivation behind the development of Distributed Systems was:. Users desire to have computational power at low cost.
Need of the people working in a group to communicate with each other. Sharing of information (data). Sharing of expensive computer resources.Designing such systems became possible with the availability of cheap and powerful microprocessors andadvances in communication technology. When a few powerful workstations are interconnected and cancommunicate with each other, the total computing power available in such a system can be enormous.Advantages of Distributed Systems are:. Resource Sharing: Due to communication between connected computers resources can be shared among computers. Enhance Performance: This is due to the fact that many tasks can be executed concurrently at different computers. Load distribution among computers can further improve response time.
Improved reliability and availability: Increased reliability is due to the fact that if few computers fail others are available and hence the system continues. Modular expandability: New hardware and software resources can be added without replacing the existing resources.Unit 1 Architecture of Distributed Systems 3Inherent Limitations of Distributed SystemsThe lack of common memory and system wide common clock is an inherent problem in distributedsystems. Without a shared memory, up-to-date information about the state of the system is not available to every process via a simple memory lookup. The state information must therefore be collected through communication.
In the absence of global time, it becomes difficult to talk about temporal order of events. The combination of unpredictable communication delays and the lack of global time in a distributed system make it difficult to know how up-to-date collected state information really is.System Architecture TypesDistributed systems can be modeled into several types. Various models are used for building distributedcomputing systems. These models can be broadly classified into five categories, and they are describedbelow: 1.
Mini Computer Model, 2. Workstation Model, 3.
Workstation Server Model, 4. Processor Pool Model, and 5. Hybrid Model.1. Mini Computer ModelIn this model, the distributed system consists of several minicomputers. Each computer supports multipleusers and provides access to remote resources.
The ratio of processors to users is normally less than one.Minicomputer model is a simple extension of the centralized time-sharing system. As shown in Figure 1,a distributed computing system based on this model consists of a few minicomputers. They may be largesupercomputers as well interconnected by a communication network. Each minicomputer usually hasmultiple users simultaneously logged on to it.Unit 1 Architecture of Distributed Systems 4 Figure 1: The distributed system based on minicomputer modelSeveral interactive terminals are connected to each minicomputer. Each user is logged on to one specificminicomputer, with remote access to other minicomputers. The network allows a user to access remoteresources that are available on some machine other that the one on to which the user is currently logged.The minicomputer model may be used when resource sharing (such as sharing of information databasesof different types, with each type of database located on a different machine) with remote users is desired.The early ARpAnet is an example of a distributed computing system based on the minicomputer model.2.
Workstation ModelIn this model, the distributed system consists of several workstations; every user has a workstation whereuser’s work is performed. With the help of distributed file system, a user can access data regardless of thelocation of the data. The ratio of processors to users is normally one. The workstations are independentcomputers with memory, hard disks, keyboard and console. Workstations are connected with each otherthrough communication network.As shown in Figure 2, a distributed computing system based on the workstation model consists of severalworkstations interconnected by a communication network. A companys office or a university departmentmay have several workstations scattered throughout a building or compass each workstation equippedwith its own disk and serving as a single-user computer.It has been often found that in such an environment at any one time (especially at night), a significantproportion of the workstations are idle, resulting in the waste of large amounts of CPU time. Therefore,the idea of the workstation model is to interconnect all these workstations by a high-speed LAN so thatidle workstations may be used to process jobs of users who are logged onto other workstations and do nothave sufficient processing power at their own workstations to get their jobs processed efficiently.In this model a user logs onto one of the workstations called his or her home workstation and submits jobsfor execution.
When the system finds that the users workstation does not have sufficient processingpower for executing the processes of the submitted jobs efficiently, it transfers one or more of theprocesses from the users workstation to some other workstation that is currently idle and gets the processexecuted there, and finally the result of execution is returned to the user’s, in. Workstation.Unit 1 Architecture of Distributed Systems 5 Figure 2: A distributed system based on the workstation modelThis model is not so simple to implement because several issues must be resolved. These issues are asfollows:.
How does the system find an idle workstation?. How is a process transferred from one workstation to get it executed on another workstation?. What happens to a remote process if a user logs onto a workstation that was idle until now and was being used to execute a process of another workstation?Three commonly used approaches for handling the third issue are as follows: 1. The first approach is to allow the remote process share the resources of the workstation along win its own logged -on.users processes. This method is easy to implement, but it defeats the main idea of workstations serving as personal computers, because if remote processes are allowed to execute simultaneously with the logged-on users own processes, the logged-on user does not get his or her guaranteed response. The second approach is to kill the remote process. The main drawbacks of this method are that all processing done by the remote process gets lost and tie file system may be left in an inconsistent state; making this method unattractive.
The third approach is, migrate the remote process back to its home workstation, so that its execution can be continued there. This method is difficult to implement because it requires the system to support preemptive process migration facility.The Sprite system developed at Xerox is an examples of distributed computing systems based on theworkstation model.3. Workstation-Server ModelA workstation with its own local disk is usually called a diskfull workstation and a workstation without alocal disk is called a diskless workstation. With high-speed networks, diskless workstations have becomemore popular than diskfull workstations, making the workstation-server model more popular than theworkstation model for building distributed computing systems.Unit 1 Architecture of Distributed Systems 6 Fig 3: A Distributed System based on the workstation-server modelAs shown in Figure 3, a distributed computing system based on the workstation-server model consists ofa few minicomputers and several workstations interconnected by a communication network. Most of theworkstation may be diskless, but a few of may be disk full.When diskless workstations are used on a network, the file system to be used by these workstations mustbe implemented either by a diskfull workstation or by a minicomputer equipped with a disk for filestorage.One or more of the minicomputers are used for implementing the file system. Other minicomputers maybe used for providing other types of services, such as database service and print service. Therefore, eachminicomputer is used as a server machine to provide one or more types of services.
For a number ofreasons, such as higher reliability, and better scalability, multiple servers are often used for managing theresources of a particular type in a distributed computing system.For example, there may be multiple file servers, each running on a separate minicomputer andcooperating via the networks for managing the files of all the users in file system.In this model, a user logs onto a workstation called his or her home workstation. Normal computationactivities required by the users processes are performed at the users home workstation, but requests forservices provided by special servers (such as a file server or a database server) are sent to a serverproviding that type of service that performs the users requested activity and returns the result of requestprocessing to the users workstation. Therefore, in this model, the users processes need not be migrated tothe server machine for getting the work done by those machines.For better overall system performance the local disk of a dishful workstation is normally used for suchpurposes as storage of temporary files, storage of unshared files, storage of shared files that are rarelychanged, paging activity in virtual-memory management, and caching of remotely accessed dataAs compared to the workstation model, the workstation-server model has several advantages: 1. It is much cheaper to use a few minicomputers equipped with large fast disks that are accessed over the network than a large number of dishful workstations, with each workstation having a.Unit 1 Architecture of Distributed Systems 7 small, slow disk. Diskless workstations are also preferred to dishful workstations from a system maintenance point of view.
Software installation, backup and hardware maintenance are easier to perform with a few large disks than win many small disks scattered all over a building or campus. In the workstation-server model, since all files are managed by be file servers, users have the flexibility to use any workstation and access the files in the same manner irrespective of which workstation the user is currently logged on. Note that this is not true win the workstation model, in which each workstation has its local file system, because different mechanisms are needed to access local and remote files. In the workstation-server model, the request-response protocol described above is mainly used to access the services of the server machine. Therefore unlike the workstation model, this model does not need a process migration facility which is difficult to implement. The request-response protocol is known as the client-server model of communication.
In this model, a client process (which in this case resides on a workstation) sends a request to a serve process (which In this case resides on a computer) for getting some service such as reading a block of a file to the server executes the request and sends back a reply to the cheat that contains the result of request processing. The client-server model provides an effective general-purpose approach to the sharing of information and resources in distributed computing systems It is not only meant for use with the workstation-server model but also can be Implemented in a variety of hardware and software environments.
The computers used to run the client and server processes need not necessarily be workstations and minicomputers. They can be of many types and there is no need to distinguish between them It is even possible for both the client and server processes to be run on the same computer. Moreover some processes are both client and server processes That is, a server process may use the services of another server, appearing as a client to the latter 5. A user has guaranteed response time because workstations are not used for executing remote processes. However the model does not utilize the processing capability of idle workstations.4. Processor Pooled ModelProcessor-pool model is based on the observation that most of the time a user does not need anycomputing power but once m a while he or she may need a very large amount of computing power for ashort time. Therefore, in the processor-pooled model the processors are pooled together to be shared bythe users as needed.
The pool of processors consists of a large number of microcomputer andminicomputers attached to the network. Each processor m the pool has its own memory to load and run asystem program or an application program of the distributed computing system.Unit 1 Architecture of Distributed Systems 8 Figure 5: A distributed computing system based on processor-poor modelIn the pure processors model, the processors m the pool have no terminals attached directly to them, andusers access the system from terminals that are attached to the network via special devices. Theseterminals are either small diskless workstations or graphic terminals.A special server, called a run server, manages and allocates the processors in the pool to different users ona demand bases. When a user submits a Job for computation, an appropriate number of professors aretemporarily assigned to the job by the run server.For Example.
Download new york new york mp3. Frank Sinatra New York New York lyrics. Start spreading the news, I'm leaving today I want to be a part of it New York, New York These vagabond shoes, are longing to stray Right through the very heart of it New York, New York I wanna wake up in a city, that doesn't sleep And find I'm king of the hill top of the heap These little town blues. Download Frank Sinatra - New York, New York mp3. Play Frank Sinatra mp3 songs for free. Find your favorite songs in our multimillion database of quality mp3s 70291. Discover New York, New York Instrumental MP3 as made famous by Frank Sinatra. Download the best MP3 Karaoke Songs on Karaoke Version.
If the users computation job is the compilation of a program having n segments,. Each of the segments can be compiled independently to produce separate releasable object files;.
n processors from the pool can be allocated to this job to compile all the segments in parallel. When the computation is completed, the processors are returned to the pool for use by other usersIn the processor-pool model there is no concept of a home machine. That is, a user does not log onto aparticular machine but to the system as a whole This is in contrast to other models in which each user hasa home machine (e.g., a workstation or minicomputer) onto which he or she logs and runs most of his orher programs they by default.As compared to the workstation-server model, the processor-pool model allows better utilization of theavailable processing power of a distributed computing system. This is because. In the processor-pool model, the entire processing power of the system is available for use by the currently logged-users, whereas this is not true for the workstation-server model in which several workstations may be idle at a particular time but they cannot be used for processing the jobs of other users. Furthermore the processor-pool model provides greater flexibility than the workstation-server model in the sense that the systems services can be easily expanded without the need to install any more computers.Unit 1 Architecture of Distributed Systems 9. The professors in the pool can be allocated to act as extra servers to carry any additional load arising from an increased user population or to provide new services.However, the processor-pool model is usually considered to be unsuitable for high-performanceinteractive applications, especially those using graphics or window systems.
This is mainly because of theslow speed of communication between the computer on which the application program of a user is beingexecuted and the terminal via which the user is interacting with to system. The workstation-server modelis genially considered to be more suitable for such applications.Out of the four models describe above, the workstation-server model is the most widely used model forbuilding distributed computing systems. This is because a large number of computer users only performsimple interactive tasks such as editing jobs, sending electronic mails, and executing small programs. Theworkstation-server model is ideal for such simple usage. However, in a working environment that hasgroups of users who often perform jobs going massive computation the processor-pool model is moreattractive and suitable.In the processor pool model, the ration of processors to users is greater than one. The model attempts toallocate one or more processors to a user to complete the task.
Once the user’s task is completed theassigned processors are returned to the pool.Examples: Amoeba system is combination of workstation and processor pool models. Each user performsquick interactive response type of task on the workstation (such as editing). User can access to pool ofprocessors for executing jobs that need significant numerical computations.The Hybrid ModelTo combine the advantages of both the workstation-server and processor-pool models, a hybrid modelmay be used to build a distributed computing system. The hybrid model is based on the workstation-server model but with the addition of a pool of processors. The processors in the pool can be allocateddynamically for computations that are too large for workstations or that requires several computersconcurrency for efficient execution. In addition to efficient execution of computation-intensive jobs, thehybrid model gives guaranteed response to interactive jobs by allowing them to be processed on localworkstations of the users.
However, the hybrid model is more expensive to implement than theworkstation-server model or the processor-pool model.Unit 1 Architecture of Distributed Systems 10Issues in Distributed Operating SystemsA distributed operating system is a program that manages the resources of a computer system andprovides users an easy and friendly interface to operate the system. The typical characteristics of thedistributed operating systems are:.
System appears to its users as a centralized operating system, but it runs on multiple independent computers. Each computer may have the same or different operating system, but not visible to the users. User views the system as a virtual uniprocessor, and not a collection of distinct machines.
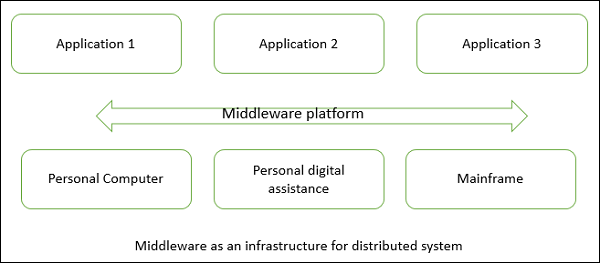
. independent This means that, architecturally, the machines are capable of operating independently. single computer: The second point is that the software enables this set of connected machines to appear as a single computer to the users of the system. This is known as the single system image and is a major goal in designing distributed systems that are easy to maintain and operate.The figure below shows a simple distributed systems for a number of applications running through different operating system where the middleware takes responsibility for the heterogeneity of the communications.Why we need a distributed system is mainly for the following reasons:.
Economics: a collection of microprocessors offer a better price/performance than mainframes. Speed: a distributed system may have more total computing power than a mainframe. Enhanced performance through load distribution. Inherent distribution: Some applications are inherently distributed. A supermarket chain. Reliability: If one machine crashes, the system as a whole can still survive.
Higher availability and improved reliability. Incremental growth: Computing power can be added in small increments. Modular expandability. Data sharing: allow many users to access to a common data base. Resource Sharing: expensive peripherals like color printers.
Communication: enhance human-to-human communication, e.g., email, chat. Flexibility: spread the workload over the available machines. Mobility: Access the system, data or resources from any place or device.A distributed system can be much larger and more powerful given the combined capabilities of the distributed components, than combinations of stand-alone systems. But it must be reliable.
This is a challenging goal to achieve because of the complexity of the interactions between simultaneously running components. To be truly reliable, a distributed system must have the following characteristics:. Fault-Tolerant: It can recover from component failures without performing incorrect actions.
Highly Available: It can restore operations, permitting it to resume providing services even when some components have failed. Recoverable: Failed components can restart themselves and rejoin the system, after the cause of failure has been repaired. Consistent: The system can coordinate actions by multiple components often in the presence of concurrency and failure. This underlies the ability of a distributed system to act like a non-distributed system.
Scalable: It can operate correctly even as some aspect of the system is scaled to a larger size. Predictable Performance: The ability to provide desired responsiveness in a timely manner.

Secure: The system authenticates access to data and servicesComputers that are connected by a network may be spatially separated by any distance. They may be on separate continents, in the same building or in the same room. Our definition of distributed systems has the following significant consequences:.
Concurrency: concurrent program execution is the norm. I can do my work on my computer while you do your work on yours, sharing resources such as web pages or files when necessary. The capacity of the system to handle shared resources can be increased by adding more resources (for example. Computers) to the network. No global clock: When programs need to cooperate they coordinate their actions by exchanging messages. Close coordination often depends on a shared idea of the time at which the programs’ actions occur. But it turns out that there are limits to the accuracy with which the computers in a network can synchronize their clocks – there is no single global notion of the correct time.
This is a direct consequence of the factthat the only communication is by sending messages through a network. Independent failures: All computer systems can fail, and it is the responsibility of system designers to plan for the consequences of possible failures.Common Examples for distributed systems include:. network file system, network printer etc.
ATM (cash machine). Distributed databases. Network computing. Global positioning systems. Retail point-of-sale terminals. Air-traffic control. Enterprise computing.
WWW.